
A Text Analysis of Alice in Wonderland
Project Description
With an aim to bring convenience to human life, artificial intelligence (AI) is not only integrated into the functioning of one’s daily life, it is also influencing what one’s life events may be. In this regard, and as suggested by a Turing test, AI needs to be further developed to understand human behavioral perspectives and cognitive processes. While studies in cognition and of the human nervous system have spawned AI technologies that mimic some functions of the human brain, replicating higher-level cognitive functions, such as developing personality and humor, identifying contextual biases, and fostering imagination still remain elusive. In part, the difficulty of reproducing these human behaviors is because the machines have not yet learned to dream. Dreams are based on the replay of past events with their spatial and temporal context, termed episodic memory, and allow one to infer logic by drawing ties to what we know and experiment with hypothetical possibilities. And it is this that allows one to self-identify context and emotion, and use this information in the process of making decisions.
Though dreams are unique to every individual, in many respects, fictional literature is the closest thing in existence to the recantation of an author’s imagination. This project seeks to determine if through a descriptive text analysis of Lewis Carroll’s Alice in Wonderland (AiW), accurate meanings of the events in Alice’s dream can be illustrated. As the author of AiW and Symbolic Logic, Carroll (a.k.a. Charles Dodgson) created a work of fiction that uses dream states to simulate a series of logic problems. By using techniques of text analysis, this project aims to identify and define connections to episodic memory in fictional literature, and propose a method for future studies which use algorithms to train machines to acquire “human-like” episodic memory.
Research design & Methods
The source material for this analysis is the 1916 illustrated edition of Lewis Carroll’s Alice in Wonderland from Sam L Gabriel Sons & Company found on Project Guttenberg. The text was downloaded directly from Project Guttenberg through R as text object—a tibble of 1,299 rows of characters in one column. A preliminary evaluation of the document, revealed a frequency skew to the word “Alice”. To account for this, Alice was added to the list of stopwords and two corpuses were created—one that included the term “Alice” and one that did not. Topic modeling with Latent Dirichlet Allocation (LDA) was used to identify clusters in the story and increase stop word lists. A sentiment analysis was used to examine the overall text for positive-negative polarity and the key emotional state. And N-grams were used to confirm the identity of the most frequently occurring characters.
Results & Reflection
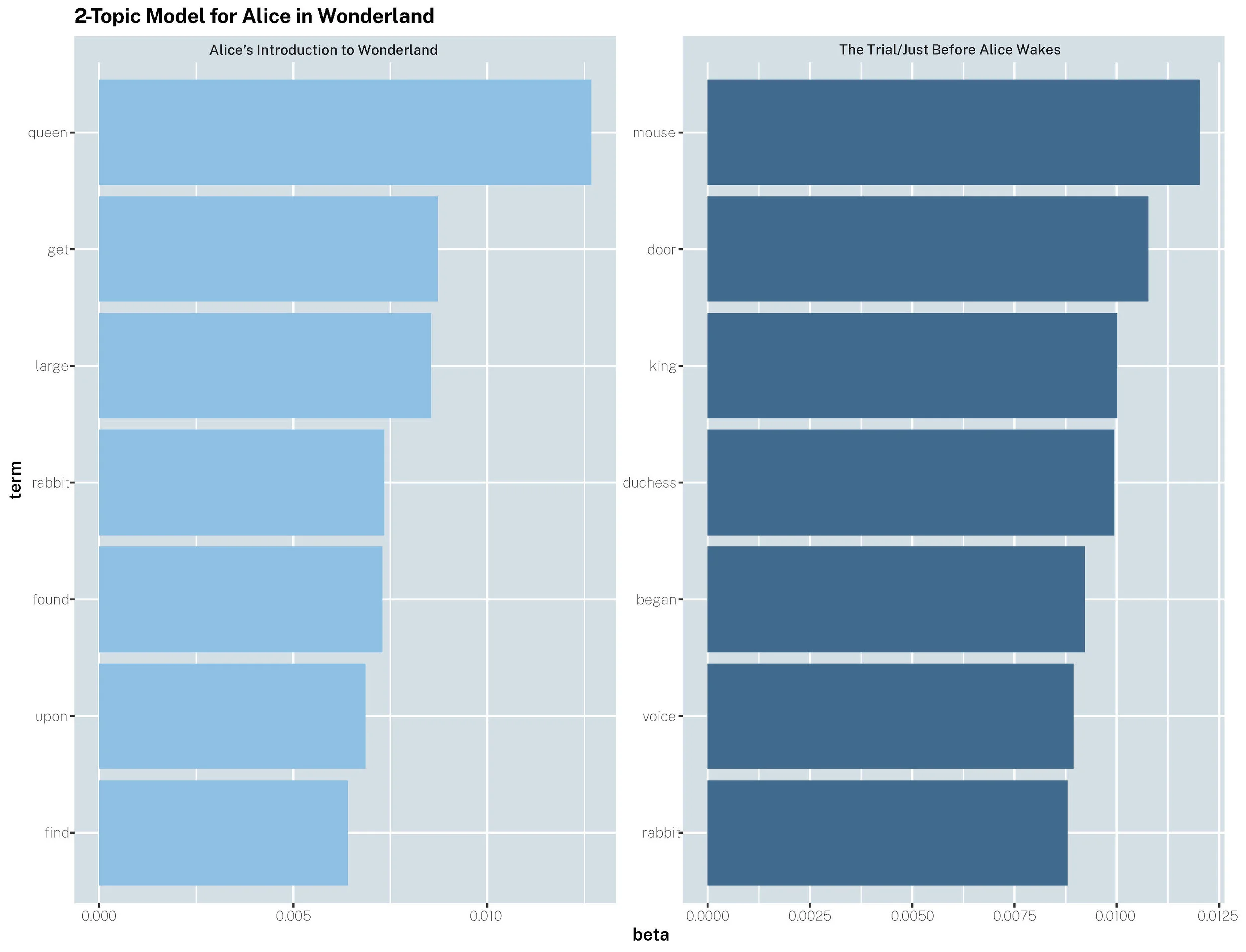
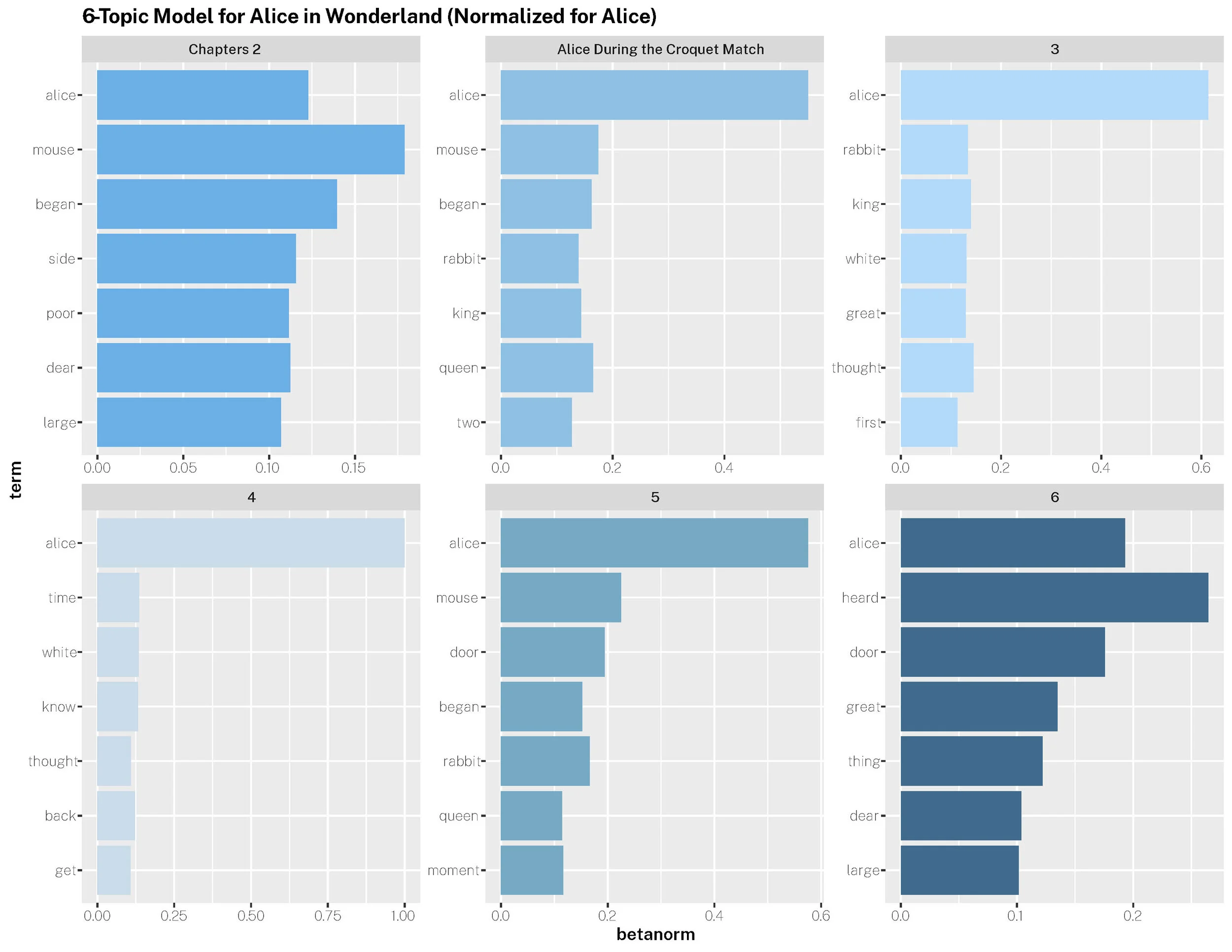
Topic Modeling
The study of two- and six-form topic models that did not include the term “Alice” were more predictive of events throughout the book. I believe the accuracy of these models would further increase as more stop words, suggested through n-gram studies, are added.

Part of an instance-based learning mechanism involves a “one-shot” rapid encoding and storage of individual experiences in a content addressable way. The location in the brain where this transfer occurs is significant because it is the juncture where one’s primitive brain and emotional brain meet—the hippocampus. While we sleep this information is then gradually transferred to the neocortex.
This pathway from episodic memory to permanent memory is dependent on sleep and replay of one’s experiences through dreams. In this replay, we draw ties to what we know and experiment with hypothetical possibilities. It is how we imagine and formulate the connections between memory and time.


Sentiment Analysis
The sentiment analysis mirrored aspects of the topic modeling, as many of the main characters (except Alice) were described. Future studies could endeavor to include Alice as a n-gram term for more varied insight on the context of events. The summary of the text provided by the Plutchik terms of sentiment analysis describe AiW as a mostly positive tale full of overwhelming anticipation, joy, and trust.


Though this study, as outlined, could not support evidence of episodic memory and was only able to partially describe the text, it did highlight design ideas for future studies of this text for episodic memory. These ideas include:
Breaking the analysis apart by chapter to see if this would differ from an overall view of the text.
Using frequency and weighted analysis to isolate main characters other than Alice. Perhaps, focusing in on them, whether individually or as a group.
Create a custom corpus that could be used as a sentiment lexicon. As characters were eliminated during the inner join with NRC, it is possible that by assigning sentiment to these characters, a more robust analysis may occur.